How much development data is enough?



Get involved with our crowdsourced digital platform to deliver impact at scale
Stay up to date:
Data Science
This article is published in collaboration with Project Syndicate.
Rapid advances in technology have dramatically lowered the cost of gathering data. Sensors in space, the sky, the lab, and the field, along with newfound opportunities for crowdsourcing and widespread adoption of the Internet and mobile telephones, are making large amounts of information available to those for whom it was previously out of reach. A small-scale farmer in rural Africa, for example, can now access weather forecasts and market prices at the tap of a screen.
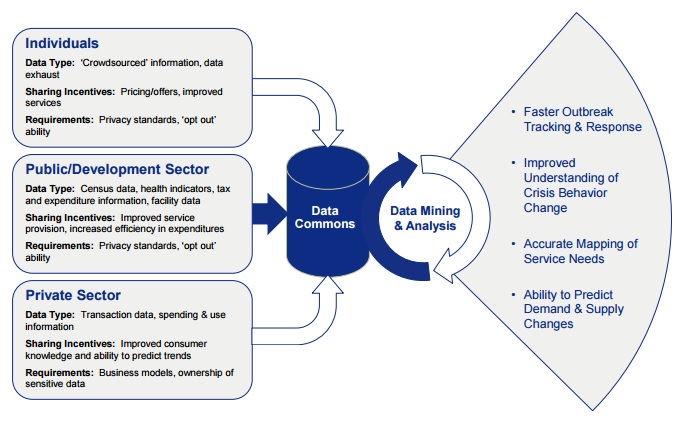
Source: ‘Big Data, Big Impact’ World Economic Forum report.
This data revolution offers enormous potential for improving decision-making at every level – from the local farmer to world-spanning development organizations. But gathering data is not enough. The information must also be managed and evaluated – and doing this properly can be far more complicated and expensive than the effort to collect it. If the decisions to be improved are not first properly identified and analyzed, there is a high risk that much of the collection effort could be wasted or misdirected.
This conclusion is itself based on empirical analysis. The evidence is weak, for example, that monitoring initiatives in agriculture or environmental management have had a positive impact. Quantitative analysis of decisions across many domains, including environmental policy, business investments, and cyber security, has shown that people tend to overestimate the amount of data needed to make a good decision or misunderstand what type of data are needed.
Furthermore, grave errors can occur when large data sets are mined using machine algorithms without having first having properly examined the decision that needs to be made. There are many examples of cases in which data mining has led to the wrong conclusion – including in medical diagnoses or legal cases – because experts in the field were not consulted and critical information was left out of the analysis.
Decision science, which combines understanding of behavior with universal principles of coherent decision-making, limits these risks by pairing empirical data with expert knowledge. If the data revolution is to be harnessed in the service of sustainable development, the best practices of this field must be incorporated into the effort.
The first step is to identify and frame frequently recurring decisions. In the field of development, these include large-scale decisions such as spending priorities – and thus budget allocations – by governments and international organizations. But it also includes choices made on a much smaller scale: farmers pondering which crops to plant, how much fertilizer to apply, and when and where to sell their produce.
The second step is to build a quantitative model of the uncertainties in such decisions, including the various triggers, consequences, controls, and mitigants, as well as the different costs, benefits, and risks involved. Incorporating – rather than ignoring – difficult-to-measure, highly uncertain factors leads to the best decisions.
When put in the service of sustainable development, such a model will often involve projecting the impact of interventions on livelihoods and the environment over several decades. This process is most successful when stakeholders as well as experts are recruited to identify the relevant variables and their relationships. These participants must be trained to provide quantitative estimates of their uncertainty for the different variables. For example, experts might estimate with 90% confidence, based on available data and their own experience, that farmers’ average maize yields in a given region are 0.5-2 tons per hectare.
The third step is to compute the value of obtaining additional information – something that is possible only if the uncertainties in all of the variables have been quantified. The value of information is the amount a rational decision-maker would be willing to pay for it. So we need to know where additional data will have value for improving a decision and how much we should spend to get it. In some cases, no further information may be needed to make a sound decision; in others, acquiring further data could be worth millions of dollars.
This process is repeated until there is no further value in acquiring data and a sound decision – a logical conclusion, based on the information, values, and preferences of the decision-makers or decision-making body – is reached. It provides decision-makers and stakeholders insights into how to improve policies to maximize positive outcomes and reduce risks, such as the possibility of low rates of adoption or limited institutional capacity for effective implementation.
It is not enough simply to assume that the data revolution will benefit sustainable development. Ensuring that it does will require recognizing the importance of rigorous analysis in every data-collection effort and the formation of a new generation of decision scientists to work alongside policymakers.
Publication does not imply endorsement of views by the World Economic Forum.
To keep up with the Agenda subscribe to our weekly newsletter.
Author: Keith D. Shepherd leads the Science Domain on Land Health Decisions at the World Agroforestry Center (ICRAF), Nairobi, Kenya.
Image: A man types on a computer keyboard in Warsaw. REUTERS/Kacper Pempel/Files.
Don't miss any update on this topic
Create a free account and access your personalized content collection with our latest publications and analyses.
License and Republishing
World Economic Forum articles may be republished in accordance with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License, and in accordance with our Terms of Use.
The views expressed in this article are those of the author alone and not the World Economic Forum.
The Agenda Weekly
A weekly update of the most important issues driving the global agenda
You can unsubscribe at any time using the link in our emails. For more details, review our privacy policy.
More on Industries in DepthSee all

Robin Pomeroy
April 25, 2024

Daniel Boero Vargas and Mandy Chan
April 25, 2024

Abhay Pareek and Drishti Kumar
April 23, 2024

Charlotte Edmond
April 11, 2024

Victoria Masterson
April 5, 2024

Douglas Broom
April 3, 2024