AI is hitting a wall. Here’s how we rethink the hardware to break it

AI is hitting a memory wall Image: REUTERS/Toby Melville
Kaushik Roy
Edward G. Tiedemann Jr. Distinguished Professor of Electrical and Computer Engin, Purdue University- Artificial intelligence (AI) is hitting a “memory wall” that slows performance and drives up costs, ultimately limiting progress.
- Standard computer architecture, in which memory and processing are separate, is becoming inefficient in the face of AI's rapid growth.
- Alternative models to combat the AI bottleneck could include compute-in-memory systems, brain-inspired spiking neural networks, event-based sensors or using lower-precision or approximate computing.
Artificial intelligence (AI) is running into a physical bottleneck. As models grow larger and more complex, an increasing share of time and energy is spent moving data between memory, where information is stored, and processors, where calculations are performed.
That burden, often called the “memory wall,” is becoming a serious constraint. The pressure is rising quickly: language-processing models grew 5,000-fold in size over four years.
The memory wall problem matters for two reasons.
First, the energy demand of large-scale AI systems is increasing rapidly, driving up costs and the infrastructure needed to train and run them.
Second, many valuable uses of AI depend on fast decisions made locally on edge devices rather than in the cloud, in settings where power, size, connectivity and delay all matter.
Medical devices, autonomous vehicles or rescue drones cannot always rely on sending information to a distant data centre for processing and waiting for a response; instead, they often need hardware that makes on-device AI more practical.
As we described in Frontiers in Science, there are three main ways to ease this bottleneck: move computation closer to the data, draw on the brain’s event-driven information-processing method and use lower-precision or stochastic computing where exact arithmetic is unnecessary.
Together, these approaches could support a new generation of AI hardware that is faster, more efficient and better suited to large-scale infrastructure and edge applications.
3 new approaches to break the AI memory wall
1. Bring computation to memory
Most computers still use the long-established von Neumann architecture, in which memory and processing are physically separate. To perform even a simple operation, data must be fetched from memory, processed in a separate computing unit, and written back again.
That repeated traffic becomes expensive for AI, which depends on enormous numbers of parameters and intermediate values that must be accessed repeatedly.
One response is compute-in-memory, which performs operations within or very near the memory array rather than moving data to a separate processing unit each time a calculation is needed. The reduction in data traffic could help cut latency and energy use as AI systems scale.
There is no single hardware recipe for compute-in-memory. A range of approaches exists, each with trade-offs in speed, precision, density and energy efficiency. The broader point is that future AI hardware will need tighter integration between storage and computation than conventional systems are designed to provide.
2. Learn from the brain’s timing
A second route involves changing how information is processed. Many AI systems rely on artificial neural networks that process inputs continuously, performing large numbers of calculations at every step, whether the incoming signal has changed or not.
Biological brains work differently – neurons are usually quiet and fire mainly when there is something to report.
The brain’s timing-based strategy has inspired spiking neural networks in which information is represented through discrete “spikes” or events. This means computation can be driven by changes in the input and when little changes, little may need to be processed.
These neural networks can be especially useful when paired with event-based sensors. A conventional camera captures image frames at regular intervals, resulting in a great deal of repeated visual information.
In contrast, an event-based camera records only pixel-level changes, such as motion or brightness shifts, resulting in a much leaner data stream. These devices require hardware and algorithms that can process changes as they occur, rather than repeatedly analyzing full images.
For edge AI, this combination is attractive. A search-and-rescue drone navigating through smoke, debris or unstable terrain may need to detect motion, avoid obstacles and adjust its path in real time with limited battery power.
Sending that information to the cloud can slow responses, especially when connectivity is unreliable. In such settings, brain-inspired processing can reduce unnecessary computation and keep sensing and decision-making local.
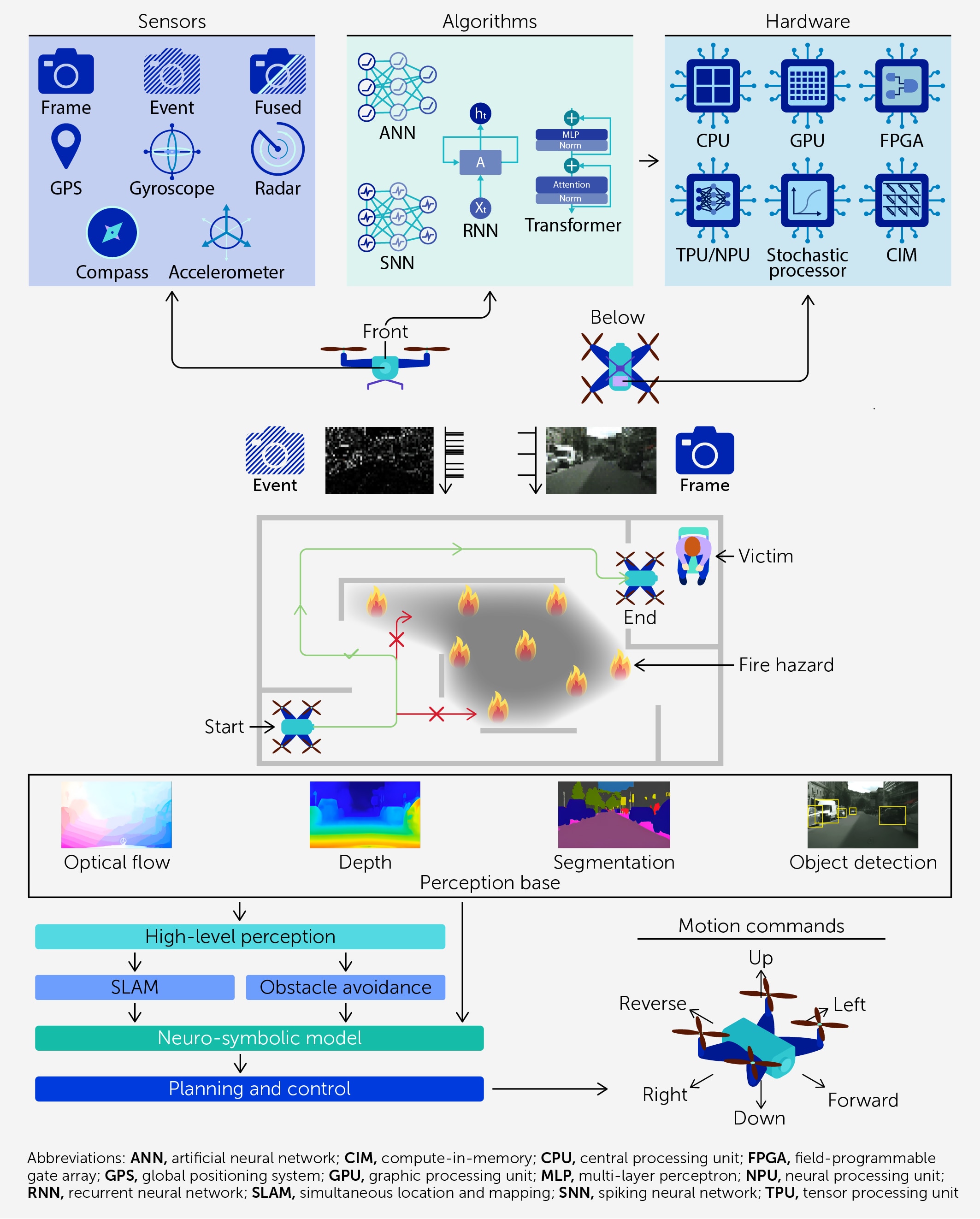
3. Use precision where it matters most
A third strategy is to recognize that not every AI computation requires the same level of precision. Many models can tolerate small numerical errors, approximate values or a degree of hardware noise without a meaningful drop in overall performance.
Tolerance for small errors creates room for stochastic or approximate hardware. In practice, this can mean using lower numerical precision, allowing controlled variability in certain operations or designing circuits that trade exact arithmetic for lower power consumption.
The aim is to match precision to need. When that balance is chosen carefully, hardware can use less power and fewer chip resources while still meeting the application's accuracy requirements.
Stochastic and approximate approaches are especially relevant for adaptive and real-time systems, such as autonomous vehicles, mobile robots or wearable devices, where fast responses and efficient operation may matter more than maximum numerical precision at every stage.
Co-designing the full system
These three routes are most powerful when treated as parts of a single design problem. Future AI hardware cannot be developed by designing a chip in isolation and then trying to fit algorithms onto it afterwards. The architecture, memory, precision strategy, sensors and learning model all shape one another.
That is why hardware-algorithm co-design is becoming so important. Some workloads may benefit most from compute-in-memory; others may benefit from spiking networks and event-based sensing; and still others may rely on mixed-precision or stochastic methods. In many cases, the best solution may combine these approaches on the same platform.
The larger implication is that the future of AI depends as much on hardware design as on model design. More efficient AI hardware could help contain the growing resource demands of large-scale systems while improving the safety and reliability of devices in the field.
This has implications for cost, infrastructure, resilience and access across sectors from healthcare and transportation to emergency response and industrial automation.
If AI is to keep spreading across the global economy without a parallel rise in energy and hardware burdens, breaking the memory wall will be essential. The next leap forward may come less from building ever-larger models and more from building better machines to run them.
Don't miss any update on this topic
Create a free account and access your personalized content collection with our latest publications and analyses.
License and Republishing
World Economic Forum articles may be republished in accordance with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License, and in accordance with our Terms of Use.
The views expressed in this article are those of the author alone and not the World Economic Forum.
Stay up to date:
Artificial Intelligence

Forum Stories newsletter
Bringing you weekly curated insights and analysis on the global issues that matter.
More on Artificial IntelligenceSee all

Piyush Verma and Andrei Covatariu
July 10, 2026




