How AI advances can enable medical research without sharing personal data

It is now possible to improve algorithms without exchanging data or AI models. Image: Unsplash.
Listen to the article
- Controversial plans in the UK to collect healthcare data led to public outcry and forced the NHS to put its plans on hold.
- This incident highlighted how vitally important issues of privacy and consent are in relation to medical research.
- Game-changing advances in machine learning that do not require data sharing are set to revolutionize healthcare.
The UK's National Health Service (NHS) recently came under intense scrutiny when it announced plans to collect and share the GP records of over 55 million patients with third parties for research purposes. It was argued that virtually every sensitive detail of patients' lives could be found in these records, including accounts of past abortions, marital problems, and substance abuse.
Although officials declared the NHS would pseudonymize the data, it is possible to identify patients regardless, prompting GPs to withhold their records and millions to opt out. The plan was set to launch in September, but public anger forced the NHS to put its data grab on hold.
The motivation to pool medical data is clear: it saves lives. Artificial intelligence (AI) has the potential to transform our understanding of biology and outperform humans in diagnosing and selecting treatments. Because AI improves when given more data, the NHS dataset could significantly impact medical research and decision making.
But centralizing millions of people's medical records is incompatible with patient privacy and therefore unethical. Not only would the NHS dataset be vulnerable to hacks and breaches, but it could also result in the misuse of data by its partners.
Unfortunately, the public debate centres on either protecting patient privacy or improving healthcare. This is a false dichotomy.
Ethical use of data for medical research
New approaches yield the same benefits as pooling data but do not rely on sharing patients' records or companies' valuable AI models. This can be achieved by carefully separating what each partner sees while still improving prediction results.
It is now possible to design algorithms that reinforce each other in their collective analyses without exchanging data. This is accomplished by calculating and sharing technical features that are meant to preserve patient privacy and the intellectual property of the underlying data and models.
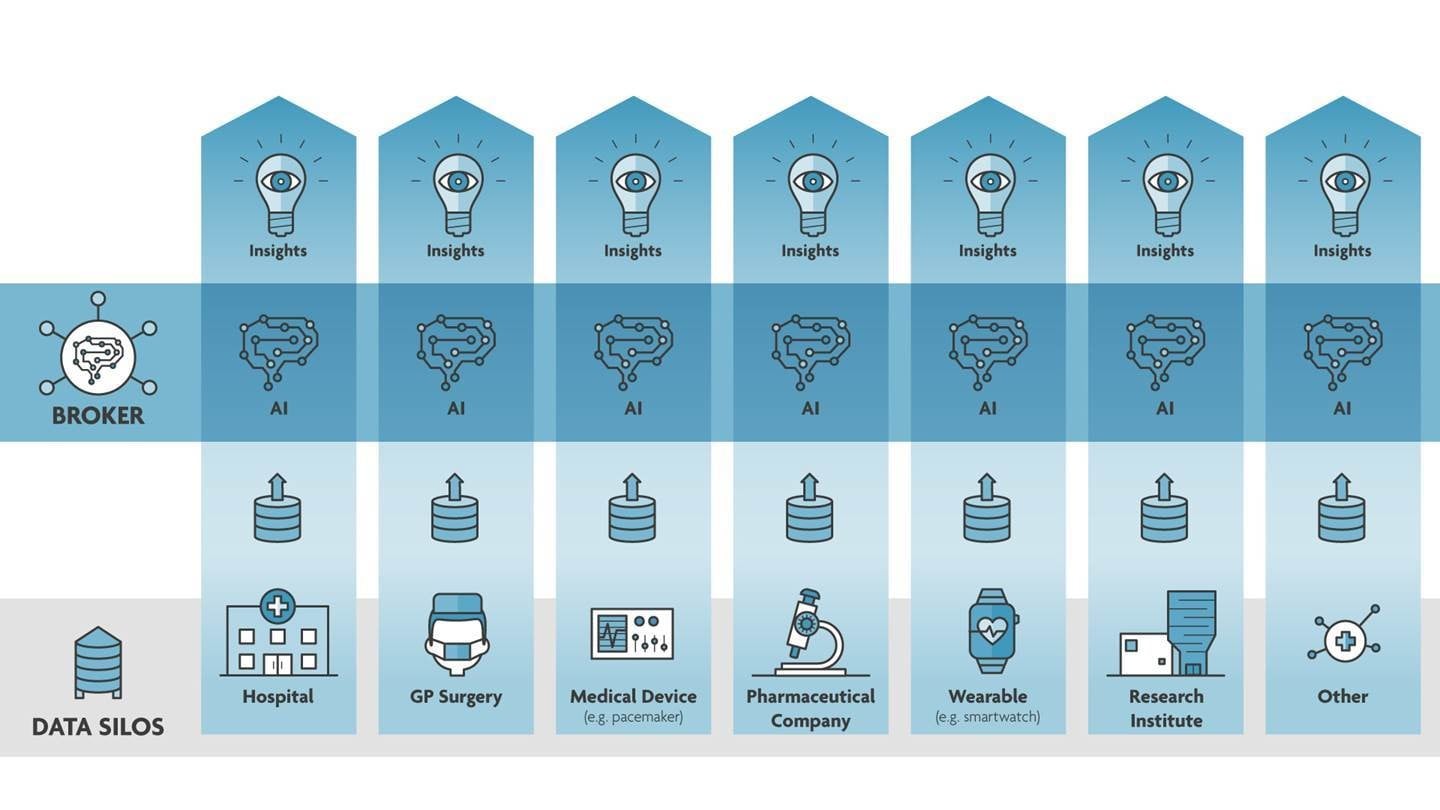
In other words, these algorithms talk to each other without actually sharing sensitive information and share their joint insights with us afterwards.
The solution, then, is clear: by pooling insights instead of data, citizens can have their privacy while companies and researchers advance medicine.
By pooling insights instead of data, citizens can have their privacy while companies and researchers advance medicine.
”The swiftness with which effective measures were mandated and vaccines were developed in response to the COVID-19 pandemic was a result of a global commitment to readily share available data. The need to share data is only amplified by the increasing dependence on AI in medicine, but potentially revolutionary insights often remain unavailable to the international research community. This is because data is stored in the individual silos of GPs, insurers, labs, hospitals, and pharmaceutical companies, often at a volume too low for AI to arrive at useful conclusions.
Sharing data is not only controversial; due to privacy laws, it is often impossible. Moreover, storing and managing data is costly, and an extensive dataset or sophisticated AI model can be extremely valuable. So why would any company or researcher share these with competitors?
Legislators can overcome these hurdles by implementing a system that allows parties to generate insights across data silos. Doing so can have a transformative impact on medical research while safeguarding patients' trust and protecting partners' intellectual property.
The world needs an independent data regulator
We believe the time is now to create an independent, neutral and transparent agency that can act as a data mediator. An ethical watchdog that supervises technical standards and connects data silos. When enough parties join, every organization will have access to increasingly powerful analytics regarding the most appropriate diagnosis or treatment.
Connecting data silos will significantly accelerate medical progress. For example, by studying the human genome at an unprecedentedly large scale, scientists can unlock new data to uncover who is at risk of developing cancer or becoming ill from infectious diseases such as COVID-19. Not only does this provide additional information on who to screen and protect preemptively, but it can also lead to new drug targets and therapies.
AI will also be crucial to counter wasteful spending. In the US, for example, cancer-related medical costs are estimated at over $208 billion a year. This should come as no surprise: immunotherapies often exceed $100,000 per patient and multiply once ancillary services are taken into account. Though immunotherapy can be highly effective, it does not work in a considerable number of cases and may cause harmful side effects. With enough data, doctors will be able to identify optimal treatments beforehand, increasing patients’ outcomes and quality of life while preventing unnecessary medical interventions and costs.
But most importantly, feeding AI models data improves their ability to save lives. However, patients are right to worry that their medical records – which contain sensitive information on their physical, mental and reproductive health – can be breached, hacked, or misused once centralized or shared. Legislators should understand that we only reap AI's full healthcare benefits when we connect data without harming privacy or commercial interests. Until then, data-sharing initiatives will be rife with controversy.
Don't miss any update on this topic
Create a free account and access your personalized content collection with our latest publications and analyses.
License and Republishing
World Economic Forum articles may be republished in accordance with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License, and in accordance with our Terms of Use.
The views expressed in this article are those of the author alone and not the World Economic Forum.
Stay up to date:
Data Science
Related topics:

Forum Stories newsletter
Bringing you weekly curated insights and analysis on the global issues that matter.
More on Health and Healthcare SystemsSee all

Mansoor Al Mansoori and Noura Al Ghaithi
November 14, 2025





